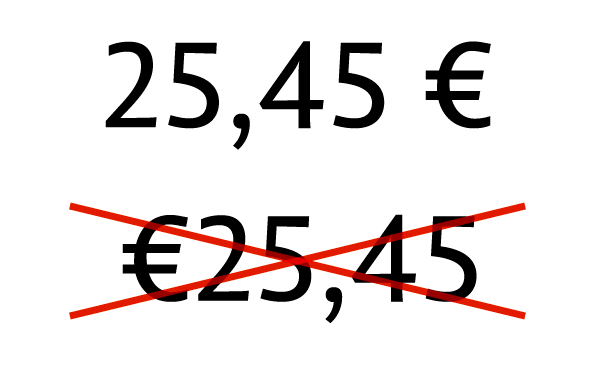Dalība Eiropas Savienībā Latvijai ir devusi ne tikai iespēju apspriest uzņemamo bēgļu skaitu un jaunu dzelzceļa līniju kartes, bet arī izbaudīt latviešu kā valsts un ES oficiālās valodas aizsargāšanas ēnas puses.
Nevienam nebūs noslēpums, ka mūsu valstī tirgoto produktu un piedāvāto pakalpojumu aprakstiem, instrukcijām un visam pārējam ir jābūt latviešu valodā. Kaut kur mums apkārt sēž desmitiem tulku, kas katru dienu pavada pie instrukciju, pamācību, regulu un (ta-dā!) programmatūras tulkošanas. Kādā citā vietā sēž kaudzīte ar valodniekiem un nozaru speciālistiem, kas ievieš latviešu valodā jaunus, skanīgus terminus, cenšoties nepieļaut spiedpogu plakandēļa, selfija un merčendaizinga ievazāšanos.
Par instrukcijām un pamācībām viss būtu skaidrs. Sākumā bija sašutums par nelietderīgi iztērēto papīru, tad samierināšanas, kam sekoja adaptācija. Tā ir tā čupiņa ar makulatūru, kurā ir jāatrod garantijas talons un ar pārējo jākurina kamīns.
Sāpe pēcpusē ir programmatūras lokalizācija. Atceros tos prieka mirkļus, kad varēju nočiept čomam nokiju un uzlikt kādu eksotisku valodu, lai pārliecinātos, cik labi viņš ir iemācījies izvēlnē uz cūceni atrast valodas nomaiņu. Šodien rodas sajūta, ka ar šādiem pašiem prieka mirkļiem sevi apdāvina katrs programmatūras ražotājs.
Tikko iznāca Windows 10. Liekam virsū, jo kāpēc gan būtu jāsēž pie vecas operētājsistēmas, ja jaunā tiek piedāvāta bez maksas. Bez jebkādiem paskaidrojumiem vai izvēles iespējām, Microsoft sarkanacaino programmētāju cilts ir izdomājusi, ka man ir jāpiedāvā Windows dzimtajā, latviešu valodā. Pagugējot (ak šie nevārdi!) izdevās noskaidrot, kā nomainīt operētājsistēmas valodu. Tik, ak mī un žē! Sākumā tak ir jāizdomā, kā tulki būs interpretējuši «Settings», «Time and language», «Region and language». Un arī tad, kad šis pārbaudījums ir izturēts, tāpat liks mīlēt dzimto valodu. Dzīves pārskats, jūs sakāt?
Microsoft Windows 10 starta izvēlne pēc sistēmas valodas nomaiņas no latviešu uz angļu.
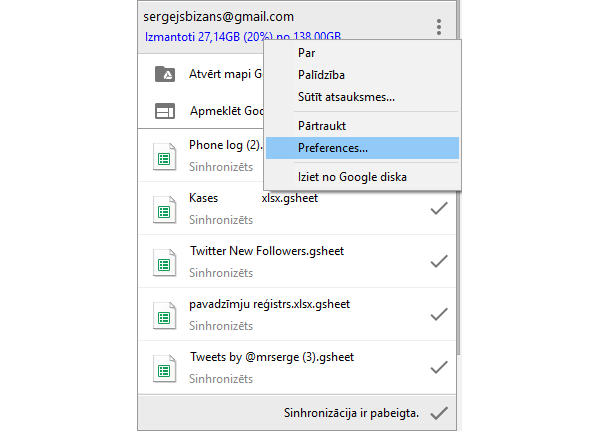
Bet Mazaismīkstais nebūt nav tas ļaunākais gadījums. Ir gadījumi, kad no lokalizācijas vispār nav iespējams atteikties. Piemēram, Google. Visas šī programmatūras giganta aplikācijas tiek uzstādītas latviešu valodā pēc noklusējuma un to nomainīt bieži vien vispār nav iespējams.
Gandrīz labi iztulkota Google Drive programmas izvēlne. Google Drive pēc uzstādīšanas nav iespējams nomainīt programmas valodu.
Šī, lielākoties uz IP adrešu ģeolokāciju balstītā, dzimtās valodas uzspiešana ir vienkārši muļķīga. Es saprotu, ka ir 21. gadsimts un elektronikas dzimtā valoda vairs nav vienīgi angļu. Ķīniešiem vienkāršāk saviem Xiaomi mobilajiem iebakstīt vienīgi mandarīnu valodu. Bet mēs neesam ķīnieši. Un tā saujiņa pasaules mēroga programmatūras, kuru izstrādā 100% latvieši ir purkšķis okeānā. Un ir ok, ja šīs dažas programmas būtu pēc noklusējuma latviski. Jo nav pieraduma spēka.
Savukārt gigantu izstrādātajām operētājsistēmām, ofisa aplikācijām, mobilajiem telefoniem vai radio vadības paneļiem pēc noklusējuma vajadzētu būt angliski. Ar iespēju pēc pirmās ieslēgšanas uzstādīt jebkādu citu valodu. Jo 90% gadījumu lokalizācija būs ar terminu tulkojumiem, kurus latvietis nemaz nezina. Jo 99,9% gadījumu tekstā būs kļūdas, kas liks improvizēt un lietot nokijas izvēlnes triku.
Augšlīgatnē, dzelzceļa līnijas Rīga – Ieriķi 65. kilometrā 2009. gada janvārī gājējiem atklāja jaunu dzelzceļa pāreju. Neviens, izņemot pašus Līgatnes novada iedzīvotājus, to nebūtu pamanījis, ja vien Miljons.com administratori neizceltos ar ceļazīmju jēgas nesaprašanu. Piecus gadus vēlāk, kad LSM.lvpublicē gājēju pārejas fotogrāfiju, to pamanu es.
Augšlīgatne. Gājēju pāreja pār dzelzceļu. Foto: Veronika Simoņenkova.
Pirmais, ko gribējās izdarīt, bija paķert spirta marķieri, iekāpt mašīnā un veikt steidzamu valodas kļūdas labojumu, paralēli izpelnoties kriminālatbildību. Veselais saprāts guva virsroku un es sākumā nolēmu noskaidrot, kā tāds teksts vispār tur parādījās.
Liriska atkāpe eParaksta faniem. Lai noskaidrotu, kas, kad un kāpēc ir uzstādījis šo zīmi, aizsūtīju elektroniski parakstītu vēstuli Valsts dzelzceļa tehniskajai inspekcijai un divu nedēļu laikā saņēmu gana izsmeļošu atbildi. vēstule VDzTI (*.pdf) un atbilde no VDzTI (*.edoc ar pielikumiem)
Gājēju pāreju projektēja Limbažu uzņēmums PRO-BET (dokumentus parakstīja J. Roops un D. Skrastiņš), bet apstiprināja Līgatnes pagasta padome un Valsts dzelzceļa tehniskā inspekcija. Tā kā autors tieši tādai zīmei bija vai nu Roops vai Skrastiņš.
Pašam bija grūti noformulēt, kāpēc «Uzmanību vilciens!» ir aplams uzraksts. Tāpēc (ceru, ka sēžat) palīgā nāca ultramodernā un atsaucīgā Liepājas Universitātes valodniecības profesore Linda Lauze. Ir aizdomas, ka viņa ir sastopama pilnīgi visos sociālajos tīklos un visos arī komunicē. «Uzmanību vilciens!» ir sarunvalodas atgremojums, kam zīmē nebūtu jāparādās. Analīzes procesā radās gan «Uzmanību, vilciens!», gan «Uzmanību! Vilciens!». Bet, pat iedziļinoties gramatikas zinātnes hiphopā par izteiksmes komunikatīvo tipu un runas aktu, nav iespējams tekstu «Uzmanību vilciens!» pareizi uzrakstīt, saglabājot uzstādītās zīmes vēstījuma jēgu.
Apskaidrība atnāca, netīšam nobraucot gar Brīvības ielas tramvaju depo.
Sargies auto zīme pie tramvaju depo uz Brīvības ielas.
Izrādās, ka jau 1960. gada 11. februāra laikrakstā «Cīņa» rakstā «Sargieties no vilciena!» Čiekurkalna stacijas priekšnieks stāsta par «Sargies vilciena» zīmēm uz dzelzceļa pārejām. Kas vēl interesantāk, tad arī tagad šādas zīmes uzstāda. Piemēram, Rīgā, Krustpils ielā.
Sargies vilciena zīme Krustpils ielā.
Man bija slinkums vēlreiz tramdīt VDzTI, lai noskaidrotu, kad ir uzstādīta zīme Krustpils ielā. Tomēr ceru, ka inspekcija ņems vērā manus novērojumus un turpmāk nepieļaus projektus, kuros zīmēs tiek izmantota prasta sarunvaloda.
Atsevišķi apspriedām izsaukuma zīmes nepieciešamību. Zīmju noformējumam ir sava specifika, kur no izsaukuma zīmes jāatsakās. Galvenā priekšrocība — samazinās nelietderīgās informācijas apjoms. Pagājušā gadsimta zīmju autori to zināja, tāpēc «Sargies auto» ar izsaukuma zīmi būs atrodams vien tādās zīmes, kas radītas astoņdesmitajos un vēlāk.
Par to, ka rakstīt visus tekstu ar burtiem augšējā reģistrā ir stulbums, es jau esmu rakstījis citā kontekstā. Un arī uz zīmēm tas attiecas, jo samazinās lasīšanas ātrums. Būtu forši turpmāk pie Latvijas sliežu ceļiem redzēt latviski pareizi uzrakstītu un pareizi noformētu tekstu.
Augšlīgatnes dzelzceļa pāreja. Zīme «Sargies vilciena» mrserge.lv versijā.
P.S.Miljons.com kļūdījās, pasmejot par pārejas plānotājiem. Gājēju ceļš nevar krustot dzelzceļu, tieši tāpēc tam bija pirms dzelzceļa pārejas jābeidzas un pēc dzelzceļa jāsākas atkal. Līgatnes pašvaldība sabijās un demontēja šīs zīmes. Ja toreiz pietika pacietības ņemties ar gājēju ceļa zīmju noņemšanu, varbūt tagad Līgatnes pašvaldībai pietiks pacietības, lai uzstādītu latviešu valodā pareizi uzrakstītu brīdinājuma zīmi?
Valodas tekstu korpuss pēc savas būtības ir iespaidīga datubāze ar dažādiem tekstiem. Piedevām, valodas tekstu korpuss parasti tiek sastādīts vai nu kādam konkrētam mērķim, vai kādam konkrētam laika periodam. Jebkurā gadījumā, runa ir par vienas valodas dažādu tekstu sacepumu, no kura ar pavisam vienkāršām metodēm var izvilkt sauso atlikumu par, piemēram, visbiežāk lietotajiem vārdiem. LU Matemātikas un informātikas institūts pie šāda projekta ir strādājis gadiem un šobrīd brīvi pieejams ir līdzsvarots mūsdienu latviešu valodas tekstu korpuss.
Metodika ir lieliska, jo tikai tehniski tas viss ir rakstītais teksts: 55% periodika, 20% daiļliteratūra, 10% zinātniski teksti, 8% normatīvie akti, 5% citi teksti, 2% Saeimas stenogrammas. Tātad uz aptuveni 4,5 miljoniem vārdu, kas datubāzē iekļauti, mēs atradīsim gan to, kā Ingmārs Līdaka «Aizver muti!» izbļāva, gan to, kā Gundega Repše juka prātā «Dienā»:
«Būtu komiski ķecerīgi šai pavasarī apcerēt latviešu literatūras eksistenciāli konceptuālo peripetiju fokusēšanos paraliteratūras metaforikas diskursīvajā orbītā un rast pārliecību par tās evidenci globalizācijas strukturētajos fokusos.» «Domas bez kompozīcijas». Gundega Repše, rakstniece. 2003. gada 29. marts, laikraksts «Diena», rubrika «Kultūra»
Kad visas šīs elektroniskās datubāzes ir aptvertas un saprastas, var sākt nodarboties ar dažādām interesantām lietām. LU Mākslīgā intelekta laboratorija ar to nodarbojas eksperimentos, kuru jēga parastam valodas lietotājam bez papildus skaidrojumiem būs maz saprotama. Bet ir arī eksperimenti, kas var būt pat ļoti noderīgi, piemēram, sava krāniņa pagarināšanai zināšanu pārbaudei. Krievu pētnieks Gregorijs Golovins ir uztaisījis krievu valodas vārdu krājuma testu «Тест словарного запаса», kuru var aizpildīt gan krievu valodu labi pārzinošs cilvēks, gan arī iesācējs. Iesaku izlasīt lielisku metodikas aprakstu, pēc kuras viņa tests ir veidots.
Задача данного теста — определить ваш пассивный словарный запас (то есть количество слов, которые вы узнаете при чтении и на слух). Единственный способ сделать это точно — взять словарь потолще (тысяч на сто слов), отметить все слова, которые вы знаете, и посчитать их.
Varbūt kādam uznāk luste, un pēc tādas pat metodikas varētu latviešu valodas testu uzprogrammēt. izejas dati tak ir pieejami un respondenti ātri uzradīsies.
Valsts valodas centrs, ne bez Latvijas Bankas līdzdalības, beidzot ir nācis pie prāta un sācis strādāt sabiedrības labā. Droši vien apzinoties savu 20 gadus ilgušo lažu, VVC tagad vienkārši to negrib atzīt un visiem publiski izziņot.
20.02.2014 | «Par vēlamo EUR pierakstu»
Pēc Latvijas Bankas iniciatīvas 2014. gada 19. februārī notika tikšanās, kurā piedalījās Valsts valodas centra, Finanšu ministrijas, Valsts kancelejas speciālisti un kuras laikā tika noteikts — Eiropas valūtas oficiālais saīsinājums (valūtas kods) EUR kā vēlamais variants turpmāk latviešu valodā rakstāms aiz summas ar saistīto atstarpi. Piemēram: 25,33 EUR (divdesmit pieci eiro un trīsdesmit trīs centi). Saskaņā ar šo lēmumu ir veiktas izmaiņas Valsts valodas centra mājaslapā 28.01.2014. publicētajā informācijā “Eiropas vienotā valūta – eiro, euro vai savādāk?”
Informāciju par Valsts valodas centra jaunumiem nav iespējams iegūt savādāk, kā vien netīšām ielūkojoties VVC mājaslapas aktualitāšu publikācijās. Nav manītas nedz publikācijas presē, nedz interneta portālos, nedz kāda preses relīze par šo visnotaļ būtisko jautājumu. Nemaz nerunājot par to, ka varētu RSS uztaisīt lapai, ko prasa 171. MK noteikumi «Kārtība, kādā iestādes ievieto informāciju internetā». Tieši tāpēc arī es ātrāk par to neko nezināju un pavēstu tikai tagad.
14.03.2014 | «Latviešu valodas ekspertu komisijas lēmums par valūtu nosaukumu pierakstu»
Valsts valodas centra Latviešu valodas ekspertu komisija 2014. gada 12. marta sēdē (prot. Nr. 33, 2. §) vienbalsīgi nolēma atbalstīt ieteikumu turpmāk konsekventi ievērot teksta vienību loģisko secību latviešu valodā un visus valūtas vienību nosaukumus – gan vārdiskos apzīmējumus (lati, dolāri, mārciņas, kronas, jenas, rubļi, eiro, u. c.), gan valūtu kodus (LVL, AUD, CAD, NZD, USD, GBP, DKK, NOK, SEK, JPY, RUR, EUR u.c.), gan grafiskos simbolus ($, £, ¥, € u. tml.) – norādīt aiz summas (ar saistīto atstarpi), kā jau minēts iepriekš, proti, Valsts valodas centra 21.02.2014. informācijā “Kā turpmāk pareizi norādīt valūtu kodus?” un 28.01.2014. informācijā “Eiropas vienotā valūta – eiro, euro vai savādāk?”.
Skaidrs, ka Eiropas Savienības Publikāciju birojs noteikumos par naudas vienību attēlošanu vēl joprojām guļ un par to neko nezina, turpinot uzskatīt, ka € vispār ir tikai ilustratīva nozīme. Pareizrakstības nodarbībās #6 ir saglabātā ES Publikāciju biroja mājaslapas kopija gadījumam, ja brīnums tomēr notiek.
Man liels prieks par komentētājiem, kas ir piedalījušies diskusijās bloga publikācijās par pareizrakstību. Šoreiz pat Valsts valodas centrs ir atzinies, ka pareizrakstība latviešu valoda ir veidojama, balstoties uz loģiku, nevis uz juristu un finansistu pieņēmumiem par to, ka «tā jau vienmēr ir bijis». VVC, lai pamatotu pašiem sev, kāpēc viņi divdesmit gadus neko nav darījuši, bija nepieciešamas veselas trīs publikācijas savā mājaslapā. Šajā publikācijā pievērsiet uzmanību tieši vārdam «loģika».
21.02.2014 | «Kā turpmāk pareizi norādīt valūtu kodus?»
Kā jau minēts iepriekš (Valsts valodas centra 20.02.2014. informācijā), Eiropas Savienības vienotās valūtas starptautiskais kods EUR latviešu valodā turpmāk rakstāms aiz summas ar saistīto atstarpi.
Ieteikums attiecas arī uz visu pārējo valūtu kodiem (USD, GBP, SEK, PLN, RUR u. tml.), kurus līdz šim bija pieņemts norādīt pirms naudas summas cipariem (skat. V. Krūmiņa, V. Skujiņa “Normatīvo aktu izstrādes rokasgrāmata”. Rīga: Valsts kanceleja, 2002, 98. lpp.; V. Skujiņa “Latviešu valoda lietišķajos rakstos”, Rīga: “Zvaigzne ABC”, 1999, 20. lpp.).
Tomēr, izvērtējot līdzšinējā regulējuma lietderību un pamatotību, kā arī konsultējoties ar Finanšu ministrijas un Latvijas Bankas speciālistiem, Valsts valodas centrs ir secinājis, ka nav loģiski norādīt valūtas kodu pirms summas, ja izrunā to nosauc aiz summas (piemēram, raksta USD 25, bet izrunā “divdesmit pieci ASV dolāri”). Šāda atkāpe no teksta vienību loģiskās secības latviešu valodā jeb izņēmuma regulējums turpmāk nebūtu atbalstāms.
Tādēļ ieteicams turpmāk konsekventi ievērot teksta vienību loģisko secību latviešu valodā un visus valūtas vienību nosaukumus – gan vārdiskos apzīmējumus (lati, dolāri, mārciņas, kronas, jenas, rubļi, eiro, euro u. c.), gan valūtu kodus (LVL, AUD, CAD, NZD, USD, GBP, DKK, NOK, SEK, JPY, RUR, EUR u.c.), gan grafiskos simbolus ($, £, ¥, € u. tml.) – norādīt aiz summas ar saistīto atstarpi.
Eiro simbola un ISO standarta pareizrakstība latviešu valodā ir ieguvusi pavisam jaunu, kā valodnieki teiktu, loģisku veidolu. Tagad atliek līdz saknei izskaust «euro» lietošanu, un vismaz ar valūtu un tās pareizrakstību latviešu valodā beidzot viss būs kārtībā.
Tehniski par € simbola lietošanu
€ — simbols (ALT + 0128)
EUR — ISO standarts (ISO 4217) U+20AC — Unicode kods € — HTML kods € — HTML nosaukums ALT+0128 — simbola ievade no tastatūras
Ja vajag lietot latviešu valodu un ir Windows, var uzstādīt klaviatūras izkārtojuma Laacz Apostrofs svaigāko versiju un tad € simbols slēpsies zem kombinācijas Labais Alt taustiņš + 4.
Ja ir atsevišķā ciparu tastatūra, tad eiro simbolu var ievadīt, pieturot kreiso Alt taustiņu un tai laikā uz ciparu tastatūras uzsitot 0128. Pēc šīs kombinācijas nospiešanas atlaiž Alt taustiņu un simbols parādās.
Ja lieto glāstekrānus, tad pārsvarā gadījumu vienkārši jāpietur taustiņš, zem kura atrodas (vairumā gadījumu) dolāra $ zīme. Tāpat kā burti ar garumzīmēm, kaut kur papildus izvēlnē būs noslēpies arī € simbols.
—
Starp skaitli un € simbolu ir jābūt atstarpei. Atstarpei vajadzētu būt nesadalāmai jeb saistītai (non-breaking space). Tomēr, ja ir redzams, ka pielietotajā garnitūrā vai atsevišķā fontā atstarpe jau ir iestrādāta (ir acīmredzams attālums starp skaitli un eiro simbolu), tad atstarpi lietot nevajag. Latviešu valodas pareizrakstība nosaka atstarpes lietojumu, tomēr primāri to nosaka cilvēka veselais saprāts, gaume un zināšanas.
REKLĀMA BNN.LV
Atbildes uz jautājumiem par reklāmas iespējām un izcenojumu, pieejamas nosūtot attiecīgās informācijas pieprasījumu uz e-pastu: reklama@bnn.lv, vai arī zvanot pa tālruņa nr. 66662861
Pārkopēju no BNN mājaslapas. Redz kur arī ekrānšāviņš, ja nu gadījumā kāds netic vai arī viņi būs kaut ko izmanījuši.
Reklāma bnn.lv 2010.10.10. 22:46.
Mans risinājums, lai pasniegtu tieši to pašu informācijas apjomu lietotājam:
Piebilde pēc raksta tapšanas: tā kā mana koncentrētā valoda sanāca ne pārāk koncentrēta, tad pilnā versija tomēr ir apgriezta un pieejama lasīšanai tikai atverot visu rakstu. Savādāk baigi daudz jāskrollējās būs, lai citus rakstus ieraudzītu, hi hi.
Kāpēc cilvēki nevar iemācīties, ka neviens masu medijs nemēdās un ir cēlies no vārda media, nevis no vārda mēdīties. media saknes ir meklējamas latīņu vārdā medium, kas nozīmē — vidus.
Valodnieki vēl joprojām stīdās, vai latviešu valodā vārds «medijs, mediji» ir iederīgs, bet tā kā nekas labāks pagaidām alternatīvs nav izdomāts, tad lietosim to, kas ir latviski pareizi, jo, piemēram, termins plašsaziņas līdzekļi ir absolūti nepatiess jau saknē.
pl. media 1. A means of mass communication, such as newpapers, magazines, radio, or television.
2. media (used with a sing. or pl. verb) The group of journalists and others who constitute the communications industry and profession.